
Security Leadership #33: Detection and Response's Scaling Problem
When volume smashes into capacity (or lack thereof).

Welcome to Issue #33 of Security Leadership Weekly! This week: security’s scaling problem. Breach post-mortem at Capita reveals a SOC that is understaffed and over capacity. Datadog relies on automation to process 10,000 pull requests per week—far more than humans can review manually. Attackers flood inboxes with thousands of Zendesk messages in a matter of hours. TikTok malware tutorials reach 500,000 views through algorithmic amplification. Across every win and loss in this week’s stories, we see an imbalance between security teams and the volume and complexity they’re asked to handle.
🛡️Tactical Challenges
Critical Asset Analysis for Detection Engineering
Detection engineer Gary Katz argues that the industry’s obsession with ATT&CK coverage percentages misses an important truth: your job isn’t to build detections for everything, it’s to figure out where to focus and what to ignore.
I’m usually not a big fan of warfare/cyber comparisons, but here the military analogy is instructive. Armies don’t try to defend entire countries; they identify strategic locations with high value (borders, airports, railways, high ground) and prioritize resources accordingly. Similarly, detection teams must start not with MITRE ATT&CK, but with critical asset identification: What are you actually trying to protect? Is it your crown jewels, custom software, domain controllers, or specific catastrophic outcomes? Leadership must prioritize these assets because there’s never enough time for everything. We spend quite a bit of time on key asset identification in the first few modules of my SOC Leadership course, precisely for this reason.
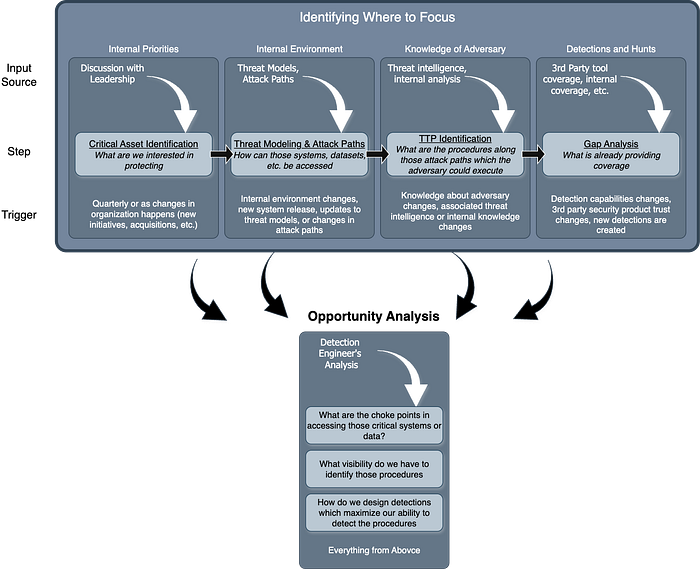
This asset-centric approach doesn’t just improve security; it transforms how you communicate value to leadership. Telling executives you have “70% ATT&CK coverage” or “1,000 detections” means nothing to them. They’ve never heard of MITRE ATT&CK, and even if they have, it doesn’t translate to business risk. Instead, show them a table of their critical systems with metrics like “detection depth” (how many points along the attack path are covered) and “maximum coverage” (detection density at key chokepoints). This contextualizes your work in terms of business priorities they understand and care about. In complex environments where everything feels critical, the only sustainable path forward is ruthless prioritization based on what actually matters to your organization’s survival.
The £14M Capita Breach
From researcher Will Thomas: The BlackBasta ransomware attack on UK outsourcing giant Capita in March 2023 offers a masterclass in how having security tools means nothing without proper processes and staffing. Despite having Trellix EDR, a SIEM, and a dedicated SOC, Capita failed to prevent the exfiltration of over 6 million individuals’ records, including passport scans, bank details, and criminal record checks. The breach resulted in a £14 million ICO fine and £20 million in recovery costs, with attackers maintaining access for nine days before deploying ransomware across 1,057 hosts.
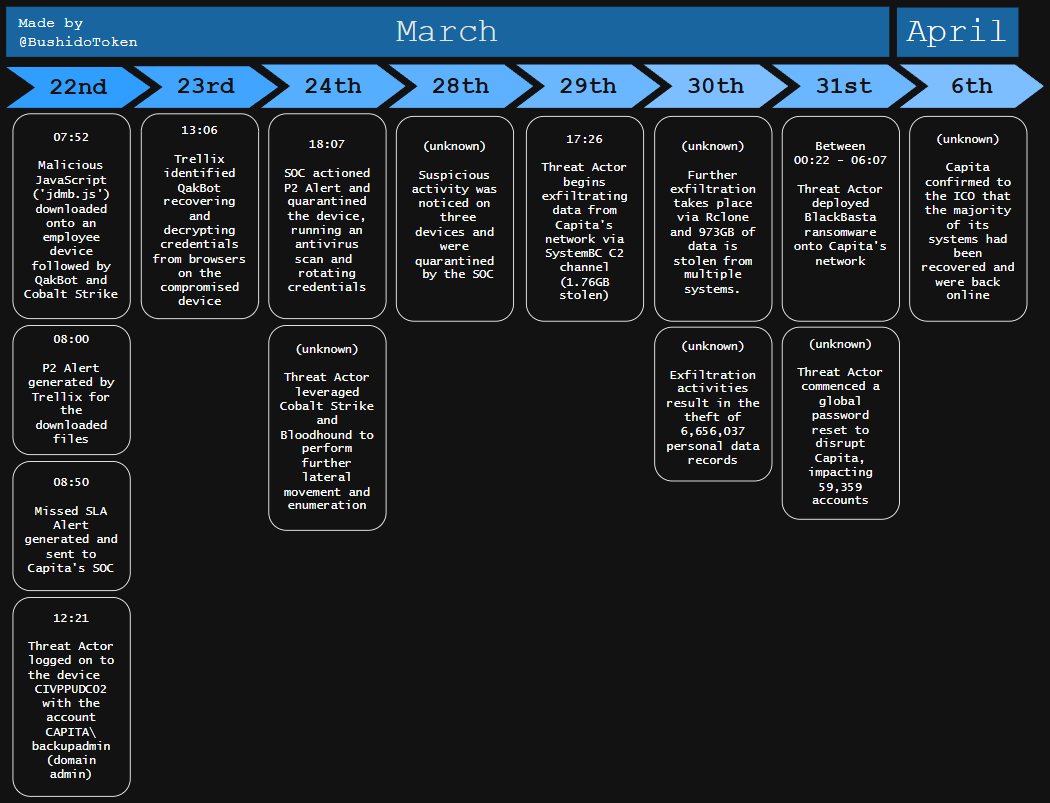
The failure points were stunning in their preventability. When the initial malicious file triggered a high-priority alert at 8:00 AM on March 22, the SOC, staffed by just one analyst per shift, didn’t act for 58 hours. By then, attackers had already escalated to domain admin privileges using a poorly secured backup service account and moved laterally across eight different domains. Capita didn’t invoke its Major Incident Management process until 7 days after the compromise - 2 days before the ransomware deployment. Even more damning: the ICO found that “at no point in the six months before or after the Incident did Capita meet their SLA for any alert level,” and multiple penetration tests had warned about Active Directory and privilege issues months before the breach.
Really great technical breakdown of the incident by Will and an exploration of the various failures in the process - a must-read for SOC leaders.
Datadog’s LLM-Powered Code Review
Cool product feature alert! Datadog now processes nearly 10,000 pull requests per week, and that number is growing rapidly, creating an attack surface that can’t be covered by manual code review alone. Traditional static analysis tools catch known bad patterns but can’t understand intent, and attackers exploit this by hiding malicious code in Base64-encoded payloads, disguising commits as bot updates, or burying exploits deep in massive dependency upgrades. In the tj-actions breach earlier this year, an attacker used a compromised personal access token to inject a malicious Python script into the popular GitHub action. Even organizations following security best practices, including code reviews, missed this entirely.
Datadog’s security team responded by building BewAIre, an LLM-powered system that reviews every PR in real time for potential malicious intent. In testing, the system achieved over 99.3% accuracy with a false-positive rate of just 0.03%. It’s now available in preview for Datadog SAST customers.
As coding assistants proliferate, security teams cannot scale their manual review capacity to keep pace with the volume of code changes. Traditional SAST and SCA tools are still useful for catching known vulnerabilities, but they can’t reason about intent or detect novel attack patterns. Datadog’s LLM-powered detection fills this gap, catching intent-based attacks that would otherwise remain invisible.
🤖 Emerging Threats
Zendesk’s Email Bomb Problem
Brian Krebs reports on a new phishing campaign exploiting the customer service platform Zendesk. By exploiting Zendesk’s default configuration that allows anonymous ticket submission without email verification, attackers are flooding targeted inboxes with thousands of menacing messages that appear to come from legitimate companies like CapCom, CompTIA, Discord, NordVPN, The Washington Post, and Tinder.
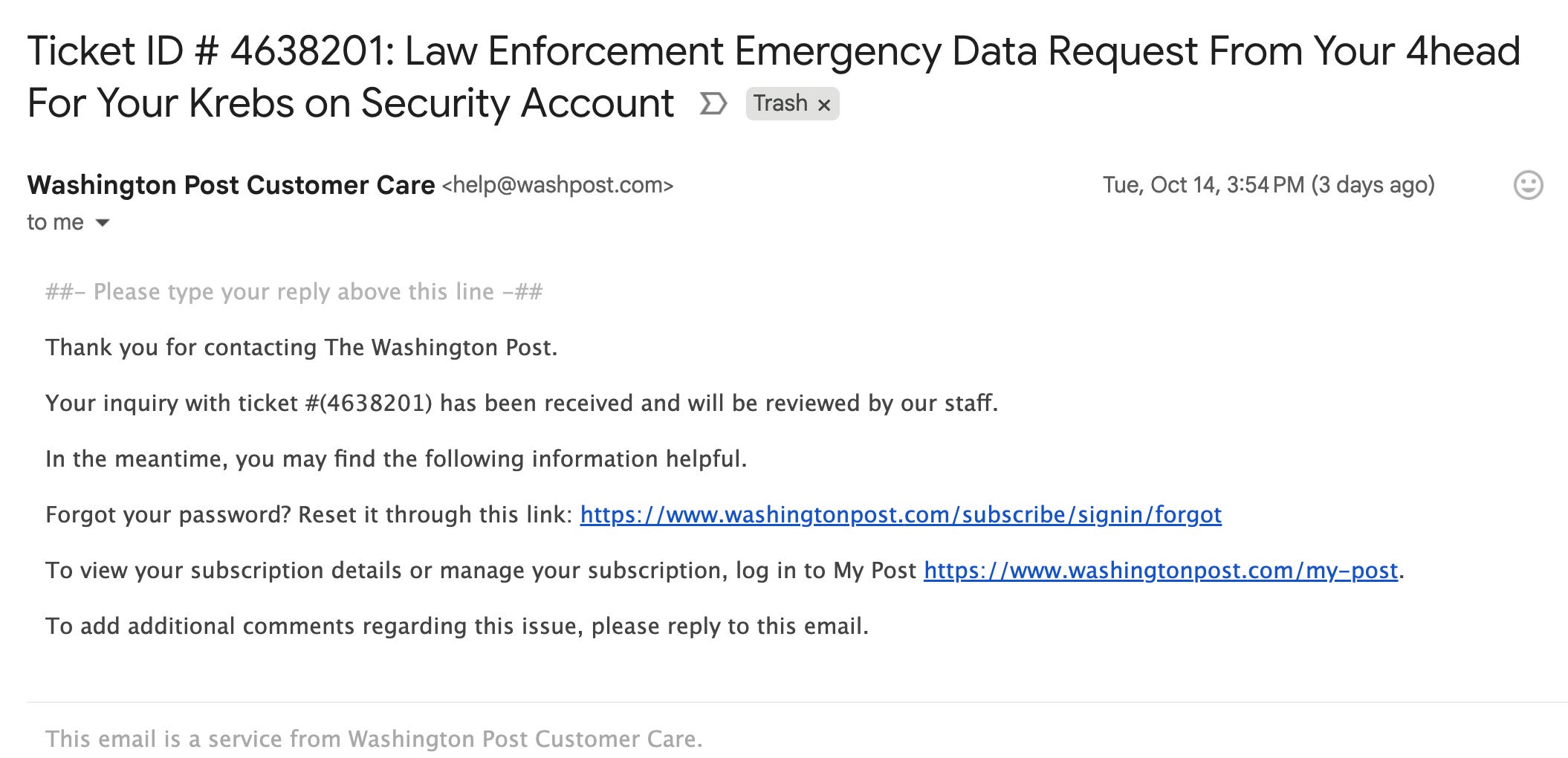
Many Zendesk customers configure their instances to allow anyone - including anonymous users - to submit support requests without email verification, then enable auto-responder triggers that send ticket notifications from their own corporate domains. When an attacker submits tickets using a victim’s email address, the victim receives correspondence that appears to be legitimate from trusted brands. Replying to these messages goes directly to the company’s support address (like help@washpost.com), not Zendesk, further sullying the brand reputation of innocent companies whose platforms are being abused.
Zendesk has acknowledged it was “leveraged…in a distributed, many-against-one manner” and is investigating preventive measures.
TikTok’s ClickFix Problem
Cybercriminals have weaponized TikTok to distribute infostealers via a ClickFix-style attack. Using videos likely generated with AI tools, attackers are tricking users into infecting themselves with Vidar and StealC information-stealing malware by running PowerShell commands disguised as software activation steps for Windows, Microsoft Office, CapCut, and Spotify. One video reached more than half a million views, while another attracted over 20,000 likes and more than 100 comments. The campaign’s effectiveness stems from exploiting users’ desire for pirated software: the videos verbally and visually guide viewers to press Windows+R, open PowerShell, and execute commands that download malware into hidden directories while excluding them from Windows Defender scans.

The ClickFix technique is dangerous even for well-defended organizations because it allows malware to execute in memory rather than being written to disk, thereby evading tools like EDR. The tactic has evolved beyond opportunistic attacks - APT groups from North Korea, Iran, and Russia have been observed utilizing ClickFix in their targeted espionage operations, with groups like MuddyWater and APT28 adopting the technique as early as October 2024. The malware’s payload is comprehensive: it creates persistence mechanisms through registry run keys, pilfers browser session cookies containing passwords and 2FA tokens, and targets cryptocurrency wallets, bank credentials, and software development environments.
The best way to identify these kinds of attacks is to instrument the browsers where they often occur, and to restrict the use of apps like TikTok on corporate assets. As luck would have it, my Push Security teammate Luke Jennings is doing a webinar on ClickFix style attacks today!
👤 People and Processes
The Cost of Cyber Leadership: Tim Brown’s Story
Tim Brown’s experience as CISO during the catastrophic 2020 SolarWinds breach offers a warning about the physical toll of cybersecurity leadership. When Russian state-sponsored hackers compromised the company’s Orion software, Brown lost 25 pounds in 20 days while managing the round-the-clock crisis response. Working through compromised communications, appearing on CNN and 60 Minutes, and fielding calls from the US Army to Operation Warp Speed, he embodied the “always-on” nature of security leadership. “The world’s on fire,” Brown recalls. “You’re trying to get information out and trying to have people understand what’s safe and what’s not safe.”
Nearly three years later, the accumulated stress nearly killed him. In October 2023, after learning the SEC had filed charges against him personally, Brown experienced what seemed like altitude sickness in Zurich. By the time he landed home, he couldn’t walk from the airport terminal to his car without stopping. He was having a heart attack. This story isn’t just about one catastrophic breach; it’s a warning about an industry that demands 24/7 vigilance while placing enormous personal liability on leaders. Brown now advocates for companies to employ psychiatrists during major incidents, recognizing the isolation of accountability. Great lessons in this article on managing burnout before and after a major incident.
💡 Connecting the Dots
The core lesson across this week’s stories is that detection and response systems built for human-scale operations are collapsing under modern volumes, and the consequences range from catastrophic breaches to long-term health issues.
The volume problem is systemic, and probably not solvable through additional effort alone. The sustainable path forward requires three admissions:
Accept human limits: You cannot manually review 10,000 PRs, staff 24/7 SOCs adequately, or defend everything simultaneously.
Augment strategically: Use AI where it excels (Datadog’s 99.3% accuracy detecting malicious intent), focus on high-quality signals, automate response (SOAR), and ruthlessly prioritize (critical asset analysis over ATT&CK completeness).
Measure what matters: Coverage percentages and SLA compliance rates mean nothing if you’re not meeting them or if breaches still happen; focus on protecting critical assets and the humans doing the protecting.
The organizations that survive won’t have the most expensive (and expansive) security stacks - they’ll be the ones that made strategic choices about what not to protect, automated relentlessly to match adversary scale, and stopped pretending human willpower can bridge the gap between detection volume and response capacity.